决策树算法
本篇主要介绍了决策树算法
算法思想
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。
其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果
对于如下数据:
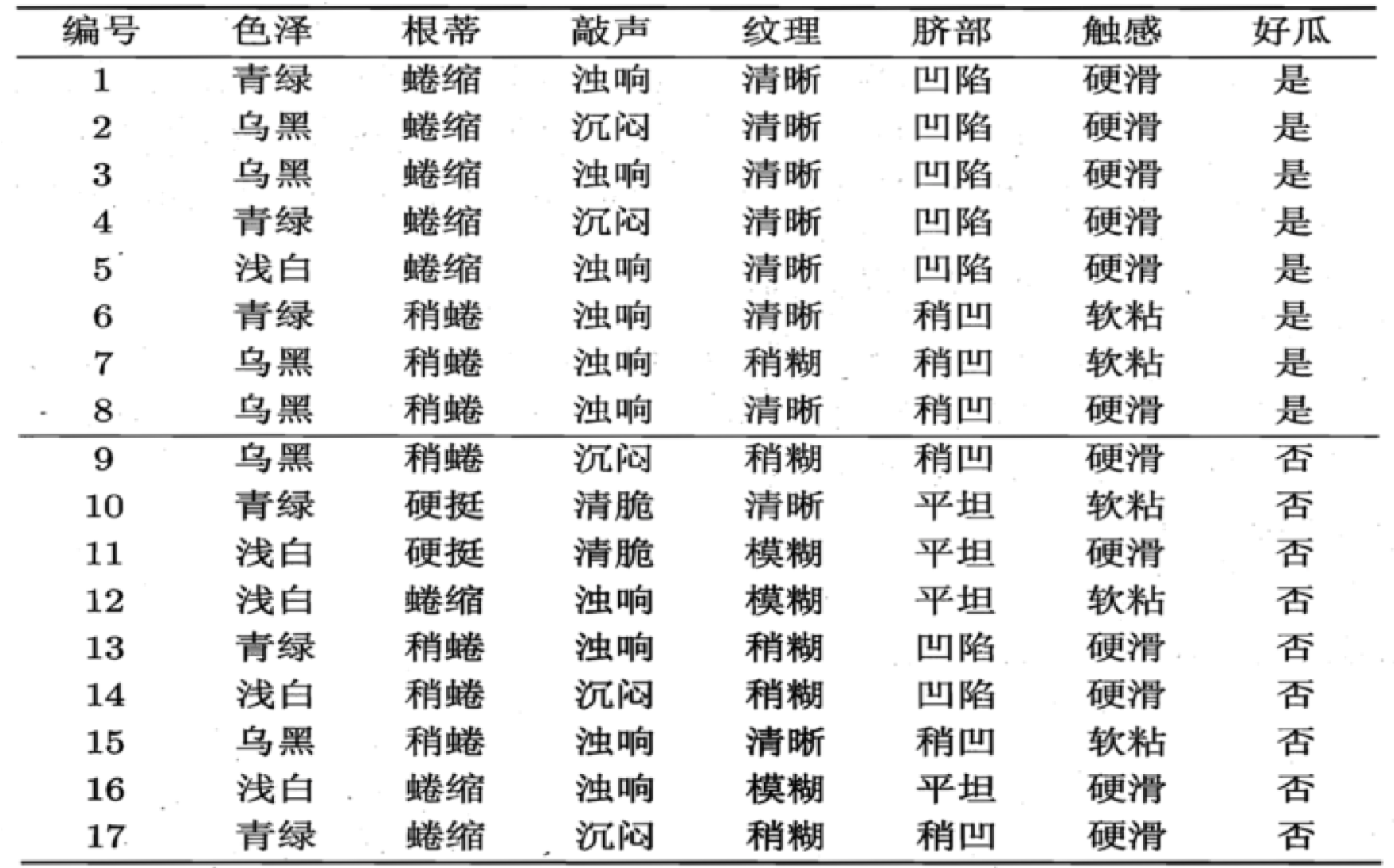
摘自 <周志华-机器学习>
算法需要解决的问题:
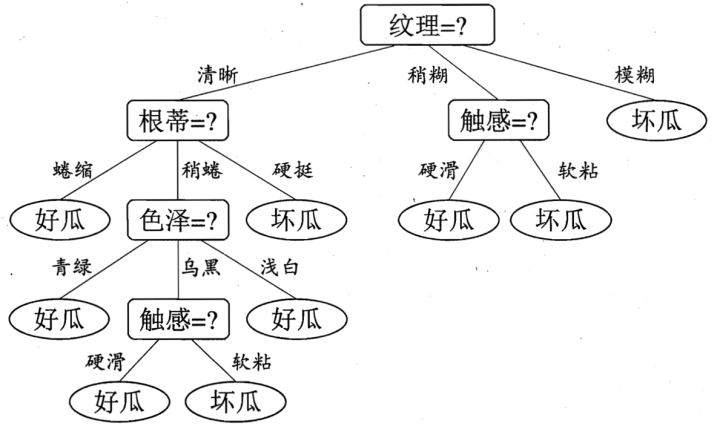
如何构建这样一棵树,为什么初始选择特征是纹理二不是选择根蒂,以什么样的标准来选择特征,这就是决策树的关键步骤分裂属性,所谓的分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。
方法:
ID3
思路:
决策树的分支节点所包含的样本尽可能的是同一类,也就是尽可能的纯。样本纯度的度量指标就是信息熵(information entropy)
\sum_{k=1}^{n}
E(D) = -\sum_{k=1}^{n}\ p_{k}log_{2}p_{k}
D: 代表样本集合D
k:代表样本的标签,类别
pk :代表样本中,k类别出现的概率
E(D) 的数值越小,D的纯度越高。
如果没有分类,那么体系的信息熵就是这个样子。但是如果我们按照属性进行分类,原来的一个系统就会变成多个。比如有一个特征(feature)包含3个数值(比如纹理包含了根蒂、触感、坏瓜)。那么如果以这个特征进行分类,原来的一个样本集合就变成了3个子样本集合,而且是互斥的。那么这个体系的熵就是这三个子样本集合( D1,D2,D3 )的代数求和
E'(D,a) = n_{D1}E(D_1) + n_{D2}E(D_2) + n_{D3}E(D_3)
E′(D,a) : 代表在样本D的基础上,选择了特征a,作为分类。其中a包含m个特征。
E(Di) : 代表在样本D的基础上,选择了特征a,作为分类。其中满足第i个特征的子样本的信息熵
nDi : 代表在样本D的基础上,选择了特征a,作为分类。其中满足第i个特征的个数
决策树的问题是,选择那个特征好呢?答案就是信息增益:
Gain(D, a) = E(D) - \sum_{i=1}^{m} \frac{n_{D_i}E(D_i)}{n}
n : 对应的D的样本总量。 信息增益越大, 说明按照a属性分类,获得的子集的纯度越高。
C4.5
增益率,其实特征的可能值会影响信息增益。比如一个特征有两个数值,那么就可以分成两个子集,如果一个特征有100个数值,就可以分成100个子集。举一个极端的例子。一个包含100个样本的测试数据包括2个特征a,b.其中a特征有两个数值,高,低, b特征有100个数值。最后需要分成两类好,坏。如果选择a特征去分类。高的子集中有好有坏,低的子集有好有坏。纯度可能会提高,但是不是100%的纯。但是如果以b特征去分类,那么100个数据,分成100个子集,肯定都是100%的纯。但是这个对于学习是没有用的。 所以引进增益率的概念。
G_ration(D,a) =\frac{Gain(D, a)}{IV(a)} \\
IV(a) = -\sum_{i=1}^{m} \frac{n_{Di}}{n} log_{2} \frac{n_{Di}}{n}
CART (Classification and Regression Tree)
每次计算log ,效率会很低,能不能有提高效率的方法?
利用基尼指数。
Gini(D) = \sum_{k=1}^{n}\sum_{k'\ne k}{n}p_{k}p_{k'}
从数据集中选择两个样本,且这两个样本标记的类别不是同一类的概率。Gini(D)越小,那么纯度越高。 思路同上,选择一个能够将体系分的足够纯的特征。 计算基尼指数
Gini_index(D, a) = \sum_{k=i}^{m}\frac{n_{Di}}{n}Gini(D_{i})
总结
根据以上方法,我们就可以根据一个训练数据集构建一棵决策树,然后就可以运用此模型对一个预测数据的类别进行估计,就是对建好的决策树模型进行遍历即可。